Synching data between two Elasticsearch clusters using a gateway
- Frank
- Elasticsearch , Gateway
- December 21, 2024
Table of Contents
How would you sync data between two Elasticsearch clusters, regardless of their versions, if you wanted to? Would you make the application write data to both Elasticsearch clusters separately? Or would you use a message queue,the application can write data to the message queue, and then have consumers for each cluster that index the data into their respective Elasticsearch instances.
Each approach has its own considerations in terms of data consistency, latency, and complexity. The choice of method would depend on your specific use case requirements and the trade-offs you are willing to make.
Introduction
The INFINI Gateway serves as a reverse proxy for Elasticsearch clusters, offering a range of functionalities including traffic control, query result caching, request logging and analysis, as well as traffic replication.
Traffic replication involves INFINI Gateway duplicating the incoming traffic to multiple clusters, which may consist of various versions of Elasticsearch or even OpenSearch, presenting an impressive capability.
Download & Deployment
Choose the suitable installation package according to your operating system and platform.
Extract the tarball to the specified directory:
mkdir gateway
tar -zxf xxx.gz -C gateway
Modify the configuration file
Download the gateway configuration here. By default, the gateway will load the configuration file gateway.yml. If you want to specify another configuration file, use the -config option.
The gateway configuration file contains a wealth of information; here, we present the key sections.
#primary
PRIMARY_ENDPOINT: http://192.168.56.3:7171
PRIMARY_USERNAME: elastic
PRIMARY_PASSWORD: password
PRIMARY_MAX_QPS_PER_NODE: 10000
PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/s
PRIMARY_MAX_CONNECTION_PER_NODE: 200
PRIMARY_DISCOVERY_ENABLED: false
PRIMARY_DISCOVERY_REFRESH_ENABLED: false
#backup
BACKUP_ENDPOINT: http://192.168.56.3:9200
BACKUP_USERNAME: admin
BACKUP_PASSWORD: admin
BACKUP_MAX_QPS_PER_NODE: 10000
BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/s
BACKUP_MAX_CONNECTION_PER_NODE: 200
BACKUP_DISCOVERY_ENABLED: false
BACKUP_DISCOVERY_REFRESH_ENABLED: false
PRIMARY_ENDPOINT: Specify the endpoint for the PROD cluster.
BACKUP_ENDPOINT: Specify the endpoint for the BACKUP cluster.
PRIMARY_USERNAME, PRIMARY_PASSWORD: The credentials required to access the PROD cluster.
BACKUP_USERNAME, BACKUP_PASSWORD: The credentials required to access the BACKUP cluster.
To initiate the Infini Gateway, just execute the gateway program as shown below.
./gateway-linux-amd64
The INFINI Gateway can operate in service mode; however, for simpler log monitoring, I ran it in the foreground. If your saved configuration file uses a different filename than the default, make sure to add the -config flag to indicate the configuration file.
Functional Testing
Submit bulk requests to the gateway, which will subsequently write the data to two Elasticsearch clusters.
# INFINI Gateway's endpoint & credentials of PROD cluster
curl -X POST "localhost:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }
'

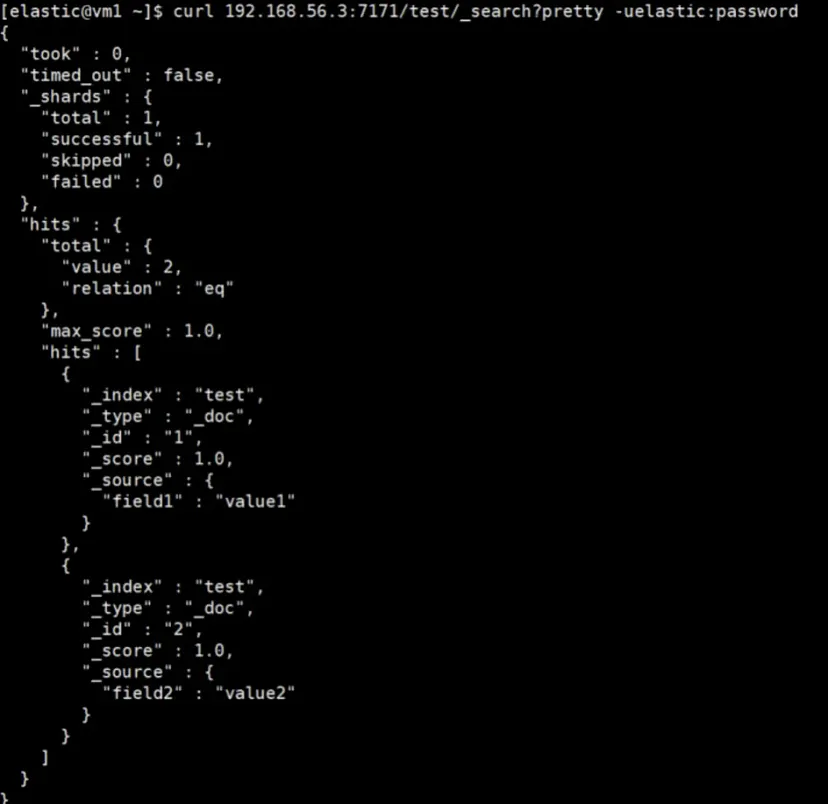
Query data from the PROD cluster.
# Endpoint and credentials of the PROD cluster
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
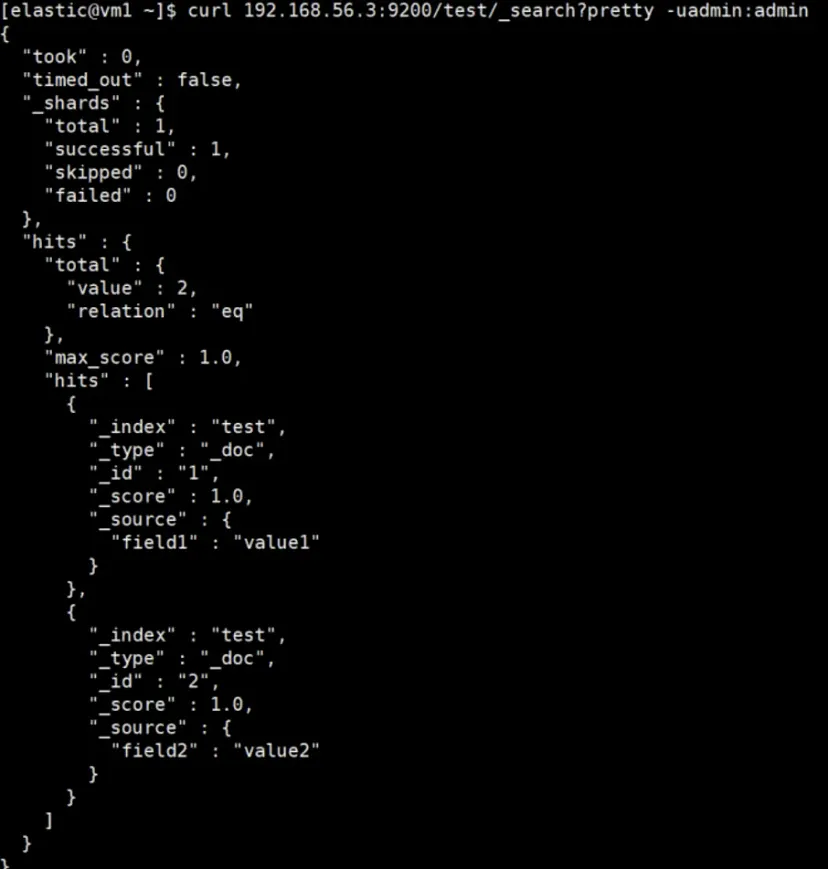
Query data from the BACKUP cluster.
# Endpoint and credentials of the BACKUP cluster
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
Query data from the INFINI Gateway.
# INFINI Gateway's endpoint & credentials of PROD cluster
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
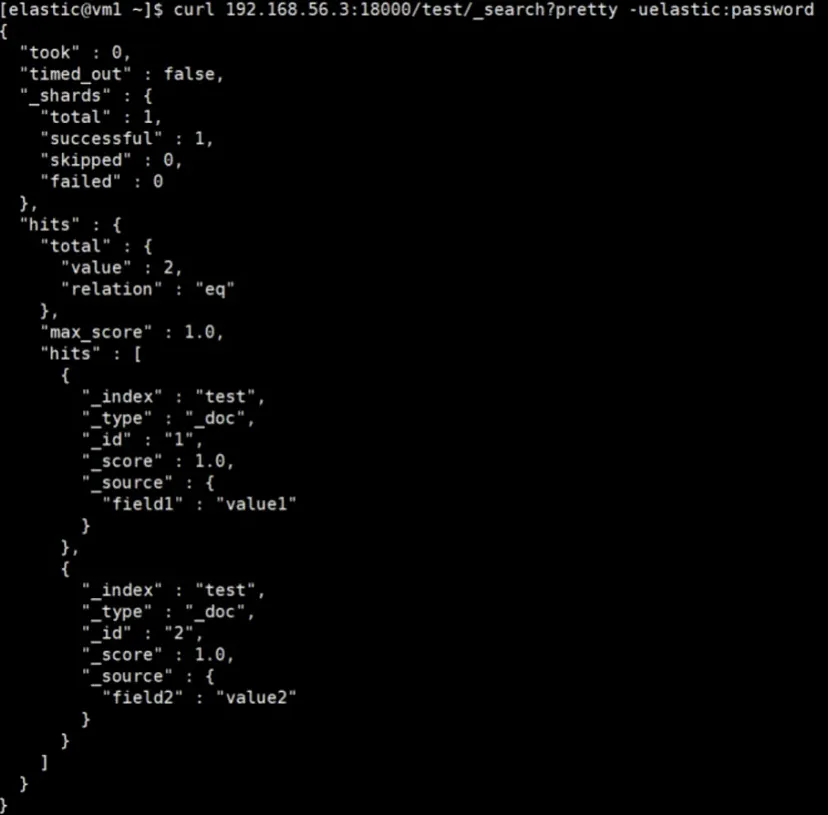
Whether you are querying data from the PROD cluster or the BACKUP cluster, you will receive the same data. You also have the option to query data directly from the INFINI Gateway, which by default forwards search requests to the PROD cluster.
In case the PROD cluster is not accessible, it will automatically redirect search requests to the BACKUP cluster. The gateway not only supports replicating write data requests but also supports delete and update data requests.
If you want to synchronize the traffic from the BACKUP cluster to the PROD cluster, deploy another gateway that acts as a proxy for the BACKUP cluster.

